Africa’s LLM Localisation Race: Who Will Own the African Language Stack?
A quiet but consequential competition is underway to build the foundational language models for Africa’s 2,000-plus languages. The outcome will shape who controls African AI for the next decade — and whether that control stays on the continent.
In February 2026, Meta released LLaMA 4 — the first major open-weight language model to include Swahili, Hausa, Yoruba, and Amharic as supported languages. The announcement generated celebration in some corners of Africa’s AI community and discomfort in others. The discomfort is worth understanding, because it maps directly to the fault line that now defines African AI’s most consequential policy question: when a Big Tech model performs well on African language tasks, does that outcome represent progress for the continent, or does it consolidate control in the hands of entities whose commercial interests and governance accountability sit elsewhere?
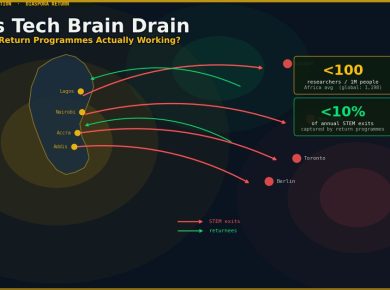
The question is not hypothetical. It is being actively debated inside Masakhane, the pan-African NLP research collective with over 300 researchers across 30 countries, and it is being answered in practice by companies like Lelapa AI in South Africa, which has spent three years building Vulavula — a commercially deployed API for Sotho, Zulu, and Xhosa — on the premise that African language AI must be built by Africans, trained on African-sourced data, and governed by African institutions. Both positions have logic. Neither is entirely right.
The Landscape: What Exists and Who Built It
Africa’s AI language landscape in 2026 is more developed than most outside observers recognise and less complete than its advocates sometimes suggest. The gap between what has been built and what the continent’s language diversity actually requires is large — but it is narrowing, unevenly, and from multiple directions simultaneously.
On the Big Tech side, Meta’s LLaMA 4 multilingual release is the most significant recent development. The four African languages included — Swahili, Hausa, Yoruba, and Amharic — are among the continent’s highest-resource languages by speaker count and available digital text. Swahili, with over 200 million speakers across East Africa, has a relatively strong presence in the Common Crawl web dataset that underpins most large-scale pretraining. Hausa, Nigeria’s lingua franca with over 150 million speakers, has been a focus of NLP research investment since at least 2019. Yoruba and Amharic follow similar patterns: well-represented in academic NLP literature, less well-represented in production-grade commercial deployment.
Google has invested in Africa NLP through its DeepMind Africa Accra lab and the Gemma model family, with African language fine-tuning capability available through the Google Cloud AI platform. Microsoft’s Azure AI language services include a subset of African languages in their translation and speech APIs. These are real capabilities with real deployment infrastructure behind them — and for a Kenyan startup building a customer service chatbot that needs Swahili NLP, they can be functional on day one.
On the African-native side, Lelapa AI represents the most commercially advanced position. Founded in Cape Town in 2022, the company’s Vulavula API delivers named entity recognition, sentiment analysis, text classification, and machine translation for isiZulu, Sesotho, and isiXhosa — three of South Africa’s eleven official languages that together cover over 30 per cent of the country’s population. Vulavula launched commercially following a seed funding round, and its API is now in production use across several South African financial services and retail deployments. The core differentiator Lelapa claims is not simply that the models were trained by Africans, but that they were trained on data sourced directly from South African communities — text that reflects actual language use, including code-switching, township slang, and dialect variation that Common Crawl cannot adequately represent.
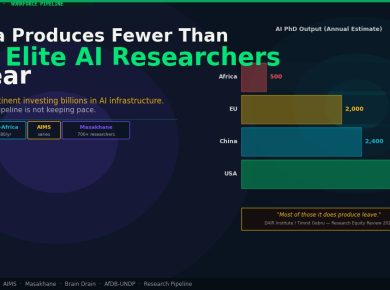
Masakhane, which has operated since 2018, occupies a different position: less commercial infrastructure, more research depth and community legitimacy. The collective has produced over 200 peer-reviewed papers, contributed to multiple multilingual model releases, and built the AfroMT translation dataset covering over 50 African languages. University labs in Nairobi, Lagos, and Kigali are active in this research ecosystem, producing graduates who now work across both the African-native startup sector and inside Big Tech Africa teams. AI4D Africa and the International Development Research Centre have provided sustained grant funding to this research layer, creating a pipeline from academic NLP to practical application that has no equivalent in most other regions.
The Commercial Question: Friend, Foe, or Infrastructure?
The Masakhane community’s internal debate about Meta’s LLaMA 4 release reflects a genuine strategic dilemma that has no clean resolution. The open-weight model is, by definition, available to African developers and researchers at no cost. A researcher in Lagos can fine-tune LLaMA 4 on Yoruba data and deploy the result on locally controlled infrastructure. That is a materially different situation from paying API fees to a closed model accessible only through a foreign cloud provider’s proprietary endpoint. Open-weight Big Tech models are not the enemy of African AI sovereignty — they can be tools for it.
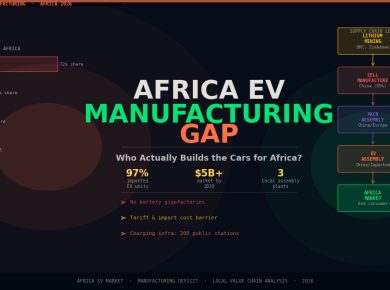
The complication is in the data and the direction of value flow. LLaMA 4’s African language capabilities were built primarily from data scraped from the open web, which means the training corpus reflects digital Africa — literate, urban, connected — not the full breadth of Africa’s linguistic diversity. The 2,000-plus languages of the continent (Ethnologue 2023) are not 2,000 equally developed NLP problems: Swahili and Hausa are high-resource by African standards but low-resource globally; most of the continent’s languages have no training data at all. An open-weight model that performs well on Swahili does not meaningfully address the language needs of a Luganda speaker in Uganda, a Shona speaker in Zimbabwe, or a Fula speaker crossing the Sahel.
For Lelapa AI, the commercial argument is that African-built models for specific language communities generate better downstream accuracy on production tasks — not because African-ness is an intrinsic quality, but because community-sourced training data captures linguistic variation that web-crawled data cannot. The Vulavula benchmark results for isiZulu sentiment analysis show meaningful accuracy gains over multilingual models trained on web-scraped Zulu text, particularly on informal and code-switched sentences. That accuracy gap has a real economic value for a South African bank deploying a fraud detection model that reads customer messages.
The harder question is scalability. Lelapa AI can build high-quality models for South Africa’s Nguni and Sotho languages because there is a viable commercial market — and because South Africa has the NLP research talent to staff the work. The same model does not easily extend to a lower-resource language community of five million speakers with no existing NLP research infrastructure and no venture-backed startup willing to absorb the cost of ground-up data collection. For those communities, Big Tech open-weight models, however imperfect, may be the only realistic near-term option.
The Sovereignty Frame and Its Limits
The African Union’s AI continental strategy, anchored by the 2026 MoU between the AU Commission and Google — covered by BETAR in March 2026 — commits to African language AI investment as a strategic priority. The MoU’s language services commitments include expanded Google Translate coverage for African languages and investment in African language data collection programmes. Critics within the Masakhane community have questioned whether an agreement that places Google as the primary delivery mechanism for African language AI infrastructure represents sovereignty or its opposite: a digitally sophisticated version of the development assistance model that has shaped Africa’s technology dependency since the 1990s.
The sovereignty frame, while politically resonant, has practical limits. AI sovereignty is not binary — it is a continuum along which any deployment sits depending on who owns the model weights, who controls the training data, who governs the inference infrastructure, and who captures the commercial value generated. A South African fintech using Lelapa AI’s Vulavula API on AWS infrastructure is more sovereign than one using Google Translate, but less sovereign than one running a locally fine-tuned model on data-centre infrastructure within South Africa’s borders. Most realistic deployments will sit somewhere in the middle of this spectrum, making pragmatic trade-offs between capability, cost, and control.
What the sovereignty frame does usefully highlight is the data collection problem. Training data for African languages does not exist at commercial scale for most of the continent’s language communities, and it will not be created by web scraping alone. It requires deliberate community-engaged data collection — a labour-intensive process that involves compensating speakers, validating linguistic quality, and managing IP rights over the resulting datasets. This is the work that Masakhane researchers and AI4D-funded programmes have been doing for years at academic scale. Scaling it commercially requires funding models that do not currently exist in most African markets.
Who Captures the Value?
If a Meta open-weight model performs well on Swahili NLP tasks, who captures the commercial value of that capability? The answer depends entirely on the deployment model. A Tanzanian startup that fine-tunes LLaMA 4 on proprietary Swahili customer data, deploys it on African cloud infrastructure, and sells it to East African enterprises captures significant value locally — even though Meta built the base model. A Kenyan developer who accesses the same capability through a Meta API endpoint, pays inference costs in dollars to a California-headquartered company, and has no visibility into the training data or model updates captures much less.
The difference is not in the base model but in the surrounding infrastructure: local fine-tuning capability, local inference infrastructure, local data assets, and the commercial relationships that convert AI capability into revenue. This is precisely where the gap between Africa’s top AI research centres — Nairobi, Lagos, Cape Town, Kigali — and the rest of the continent is most consequential. The cities with the talent and infrastructure to add local value to open-weight models are a small fraction of Africa’s 54 countries, and the benefits of the LLM localisation race are likely to cluster in those locations unless deliberate policy intervention creates different incentives.
The race to own Africa’s language stack is real. The answer to who will win it is: probably everyone and no one, simultaneously. Big Tech will continue to extend multilingual model capabilities to higher-resource African languages. African-native startups like Lelapa AI will build commercially viable products for specific language markets where the economics work. Masakhane and the academic NLP ecosystem will continue to produce research, datasets, and trained talent that flow into both tracks. The continent’s 2,000-plus languages will not all be served by any of these actors within any foreseeable timeline.
What matters most is not who builds the base models but who builds the deployment infrastructure, the training data assets, and the commercial relationships that generate African value from African language AI. That is a question less about model weights and more about investment, policy, and institutional capacity — and it is one that neither a Meta press release nor a Masakhane research paper can answer alone.
— Technology Desk, BETAR.africa