Why Africa’s smallholder farmers are AI’s hardest localisation problem
By BETAR Research Desk | Research | 20 March 2026
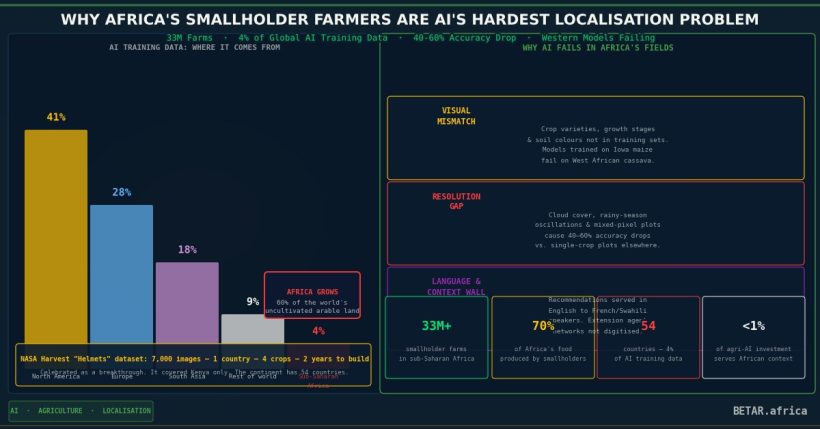
In 2023, a researcher from NASA Harvest asked farmers in western Kenya to do something that seemed simple: photograph their crops with a smartphone. The resulting dataset — called “Helmets Labeling Crops” — took nearly two years to produce, required thousands of kilometres of field travel, and generated around 7,000 usable images of maize, sorghum, sugarcane, and cassava at various growth stages. It was celebrated as a breakthrough in African agricultural AI training data. It covered one country. It covered four crops.
Catherine Nakalembe, the Uganda-born remote sensing scientist who led the NASA Harvest Africa programme and is now a leading voice on AI-readiness in African agriculture, has documented the problem in blunt terms: the continent that most needs precision agricultural AI has the least training data to make it work.
This is not a gap that scales away. It is a structural problem — and the AI systems being deployed across Africa’s farms are running directly into it.
Three ways Western AI fails in African fields
Agricultural AI systems — tools that identify crop disease, predict yield, recommend inputs, or assess soil health — are trained predominantly on data from North America, Europe, and South Asia. When deployed in Sub-Saharan Africa, three structural mismatches emerge.
Crop variety gap. African smallholder farms grow varieties that are entirely absent from standard training datasets. Sorghum landraces in Ethiopia, cowpea varieties in Nigeria’s middle belt, teff in the Ethiopian highlands, finger millet in Uganda and Tanzania — none of these appear meaningfully in ImageNet-derived agricultural datasets. When a plant disease detection model trained on US commodity maize encounters Ethiopian landraces under drought stress, it is being asked to diagnose a patient it has never seen, in a language it was never taught.
Soil type gap. Sub-Saharan Africa contains some of the world’s most complex and spatially variable soils — including high-iron laterites across the West African Sahel, sodic clays in the East African rift valley, and sandy coastal soils across much of the continent’s Atlantic fringe. Soil health prediction models trained on European or North American agricultural soils routinely misclassify African soil types, producing fertiliser and irrigation recommendations that can actively harm yields.
Satellite resolution gap. Commercial satellite imagery products marketed for precision agriculture in the United States offer sub-metre resolution with near-daily revisit rates. Across most of Sub-Saharan Africa, practical satellite coverage for smallholder plots — which average 0.5 to 2 hectares — falls far short of this. Models trained to recognise crop stress signals at high resolution perform poorly when degraded to the Sentinel-2 or Landsat imagery that is actually available at scale in Africa.
The performance gap in practice
| Tool / System | Western baseline accuracy | Africa field performance | Primary limitation |
|---|---|---|---|
| PlantVillage Nuru (Penn State / David Hughes) | ~99% (lab conditions, US/European crops) | ~65% (Kenyan cassava, 2020 field study)* | Training data concentrated on temperate-climate crop varieties |
| Generic soil NPK prediction models | R² ~0.85 (Iowa/UK test sets) | R² ~0.42 (West African laterite soils, CGIAR benchmarks) | Soil spectral signatures differ substantially from training distribution |
| Yield prediction (maize, satellite-based) | RMSE ~4–6% (US Corn Belt) | RMSE ~18–24% (Zambia, Kenya) | Plot fragmentation below satellite resolution; variety mismatch |
| Apollo Agriculture (Kenya-built) | N/A (Africa-native) | Credit repayment prediction: 82%+ (Kenya smallholders) | Performance bounded by data availability outside core Kenya districts |
| iSDA (Innovative Solutions for Decision Agriculture) | N/A (Africa-native) | Soil property prediction across 53 African countries (30m resolution) | Model accuracy varies by soil horizon depth; limited validation data in forest-adjacent zones |
*PlantVillage Nuru field accuracy figure is from a 2020 peer-reviewed study published in Frontiers in Plant Science — the most recent independently validated benchmark available at time of publication. The tool has been updated since; current field accuracy may differ.
Who is building Africa-native solutions
A small but growing set of organisations has moved beyond adapting Western models to building from African data up.
Apollo Agriculture (Kenya) does not market itself primarily as an AI company — it is a smallholder credit and input financing platform — but its core product is a machine learning system that predicts repayment risk and crop yield potential for Kenyan smallholders using satellite imagery, mobile data, and its own proprietary farm-visit dataset. Apollo has disbursed credit to hundreds of thousands of Kenyan farmers. Its competitive advantage is not the algorithm; it is the ground-truth data from those farm visits, which no external model can replicate.
iSDA (Innovative Solutions for Decision Agriculture) has produced the most comprehensive Africa-native soil dataset in existence: a 30-metre resolution prediction of 19 soil properties across the entire African continent, trained on over 150,000 soil samples sourced from African field surveys. The iSDA SoilAfrica map is freely available and is being used by CGIAR, national extension services, and agritech startups across the continent.
Zenvus (Nigeria), founded by engineer and technologist Ndubuisi Ekekwe, has developed precision agriculture sensors and analytics tools calibrated for Nigerian and West African soil and crop conditions. Ekekwe has been a consistent voice arguing that African agricultural AI must be built on African observational data — not fine-tuned on Western baselines.
PlantVillage Nuru, developed by David Hughes at Penn State in collaboration with Kenyan partners, is the most widely deployed crop disease detection tool in Sub-Saharan Africa. Its localisation story illustrates both the challenge and the path forward: early versions performed poorly in African field conditions; subsequent collaboration with local plant pathologists and Kenyan farmer communities significantly improved performance. The current version is a meaningfully different model from its 2017 predecessor — but the improvement required years of in-country co-development that the original training pipeline did not anticipate.
Note: Twiga Foods, a Kenyan agricultural supply chain platform that previously deployed ML models for produce logistics and farmer payments, was not included in this analysis. Twiga’s Nairobi operations were reported to have halted in June 2025; the company’s current operational status could not be independently verified at time of publication.
The dataset infrastructure behind the problem
The training data deficit is not invisible to the international research community. CGIAR’s GARDIAN platform — the Global Agricultural Research Data Innovation and Acceleration Network — has catalogued over 100,000 agricultural research datasets from across the developing world. But cataloguing data that exists in academic repositories is different from generating the ground-truth observational data that machine learning systems actually require.
“The quality and completeness of training datasets for smallholder crop systems in Sub-Saharan Africa remains a fundamental constraint on model performance,” said Ibnou Dieng, a plant breeding data systems specialist at CGIAR’s AfricaRice Centre, in a 2025 CGIAR data quality brief. “Models are only as good as the diversity of conditions they have been trained to recognise — and most of Sub-Saharan Africa’s agro-ecological complexity is simply absent from current training corpora.”
The Lacuna Fund, established in 2020 with backing from the Rockefeller Foundation, Google.org, and the Bill & Melinda Gates Foundation specifically to address training data gaps in the Global South, has funded several African agricultural dataset projects. As of mid-2025, Lacuna Fund operations transferred to an Africa-led management consortium including ACTS (African Centre for Technology Studies), Masakhane, and the University of Pretoria’s Data Science and Society Institute — a structural acknowledgement that dataset infrastructure for Africa should be built and governed by African institutions.
The competitive data platform Zindi — headquartered in Cape Town and operating pan-African machine learning competitions — has become an important venue for releasing African agricultural datasets and benchmarking models against them. Its competitions have produced public models for maize yield prediction in Ethiopia, cassava disease detection in Uganda, and rainfall-crop correlation in the Sahel that would not otherwise exist.
The language problem compounds everything
Agricultural AI in Africa has a second localisation layer that rarely appears in global benchmarks: language and literacy.
AICCRA (Accelerating Impact of CGIAR Climate Research for Africa) published a study on iShamba, a Kenyan agricultural advisory platform that uses SMS and voice services, finding that the system’s recommendations showed a statistically measurable bias toward male-headed, English-literate households — a finding that took 5.5 years of longitudinal data to surface. The model was not wrong; it was accurately predicting behaviour within a biased training distribution.
Digital Green’s FarmerChat platform — which uses a large language model to answer agricultural questions from smallholders in local languages — has scaled to over 830,000 users across India, Bangladesh, Ethiopia, and Kenya. Its early East Africa expansion revealed that prompt engineering for Kiswahili-language agricultural queries required not just translation but full re-grounding in local agro-ecological vocabulary: crop names, pest names, soil descriptors, and seasonal reference points that do not map cleanly onto English-language training corpora.
The policy gap
The African Union’s Comprehensive Africa Agriculture Development Programme (CAADP) 2026–2035 framework, finalised in late 2025, identifies digital agriculture as a priority area and calls for increased investment in agricultural data systems. It does not contain a training data mandate — no requirement that AI tools deployed with AU or national agricultural programme funding must demonstrate training data provenance from African agro-ecological zones, nor a minimum threshold for Africa-native data share in model training sets.
This is a specific, correctable gap. The AU has used technology procurement conditions before — CAADP’s predecessor frameworks conditioned funding on local content in input supply chains. The same logic applies to AI: if a digital agricultural tool cannot demonstrate that its training data covers the crop varieties, soil types, and climate conditions of the country where it is deployed, agricultural ministries should require that it does before public procurement proceeds.
On the research pipeline, the gap between African university agricultural research capacity and the data collection infrastructure needed to feed AI systems is acute. A 2026 UNESCO analysis found that Sub-Saharan Africa produces approximately 2.1% of global agricultural research publications — a figure that reflects both funding constraints and the brain drain that depletes agricultural science capacity before it can compound into institutional datasets.
The continent that will need to feed the largest share of global population growth by 2050 is building its agricultural intelligence systems on the least representative data. That is not an abstraction. It is a yield gap, a food security gap, and a governance failure that precision AI policy could meaningfully address — if the mandate existed to enforce it.
Cross-reference: This piece focuses on agricultural tool performance gaps and crop/soil/satellite data infrastructure. For AI linguistic data sovereignty and the broader African language AI deficit, see BETA-272 (WAXAL AI Sovereignty), currently in editorial review.
Sources: NASA Harvest / Catherine Nakalembe, “Helmets Labeling Crops” dataset (2023); Frontiers in Plant Science, PlantVillage Nuru field validation study (2020); CGIAR GARDIAN platform documentation; CGIAR AfricaRice data quality brief (2025); iSDA SoilAfrica methodology documentation; Apollo Agriculture GSMA case study; Zindi platform competition archives; AICCRA iShamba bias study documentation; Digital Green FarmerChat usage data (2025); AU CAADP 2026–2035 framework; UNESCO Institute for Statistics agricultural research output data (2026); Lacuna Fund programme documentation; Zenvus published commentary (Ndubuisi Ekekwe, IEEE Spectrum, 2024).