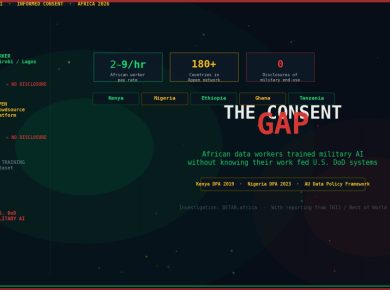
Large language models work in English. They work tolerably in French and Arabic. In Hausa — spoken by 80 million people — they largely do not. In Yoruba, Amharic, Xhosa, and most of the other 2,000-plus languages across Africa, the gap between what exists and what is needed is a fundamental infrastructure problem. A small ecosystem of companies is now building the layer that sits between raw African language data and a production-grade AI system. Who gets there first will matter enormously.
The scale of the gap is not abstract. According to recent research on large language model performance, only 42 of Africa’s 2,000-plus languages have any presence in current LLMs. Of those, just four — Amharic, Swahili, Afrikaans, and Malagasy — are consistently represented across major models. For every other African language, the AI stack effectively does not exist. A fintech deploying an AI customer service agent in Lagos for Hausa-speaking users has no usable off-the-shelf foundation model. A government rolling out AI-powered public services in Addis Ababa cannot rely on GPT-4 to handle Amharic with meaningful accuracy.
This is not primarily a model problem. It is a data pipeline problem — and behind it, an annotation labour problem, a compute access problem, and a commercial incentive problem. Fixing it requires building a stack that most of the global AI industry has no economic reason to build for Africa.
What the stack looks like — and what is missing
Producing a production-grade African-language LLM requires four things that are structurally scarce in Africa: large volumes of clean text data in the target language, human annotators who are both fluent and technically trained, GPU compute at a scale that most African startups cannot afford, and fine-tuning methodologies that extract meaningful performance from limited data.
Fine-tuning existing foundation models on African language data does produce gains — a 2024 benchmark study, “Bridging the Gap: Enhancing LLM Performance for Low-Resource African Languages” (Adelani et al., arxiv:2412.12417), found average monolingual performance improvements of around 5.6% when high-quality data is used. But those improvements are measured against models that started at a low baseline. A 5% improvement on a model that scores 40% accuracy in Swahili is not a product-grade result for a commercial deployment.
The consensus among African AI researchers is that low-resource languages — the majority of African languages — need purpose-built data pipelines and potentially purpose-built foundation models to reach commercial viability, not just fine-tuned adaptations of Western-trained LLMs.
Who is building
Lelapa AI (Johannesburg) is the most commercially advanced player in the African-language model space. Its InkubaLM, launched in 2024 and positioned as Africa’s first multilingual LLM, covers five languages: Swahili, Yoruba, isiXhosa, Hausa, and isiZulu. The model powers Vulavula, a language-model-as-a-service API offering transcription, translation, sentiment analysis, and speech synthesis. Lelapa has raised $2.5 million from Mozilla Ventures and Atlantica Ventures, with individual backing from Jeff Dean, Google’s AI chief, and Karim Beguir of InstaDeep.
NITDA and NKENNEAi represent the government-led approach. In March 2026, Nigeria’s National Information Technology Development Agency formalised a partnership with NKENNEAi — an edtech platform with 400,000 users learning African languages — to develop localised AI infrastructure covering Hausa, Yoruba, Igbo, Swahili, and Nigerian Pidgin. The partnership is backed by NITDA’s GovNet compute initiative and sits within a broader mandate to achieve 70% digital literacy in Nigeria by 2027. This is state-backed infrastructure with institutional compute behind it — a different resource profile from startup-funded approaches.
Masakhane is the open-source backbone. The pan-African NLP research community has produced baseline models and datasets covering 16 African languages, including MasakhaNER 2.0 (the largest human-annotated named entity recognition dataset across 20 African languages), MasakhaNEWS (news topic classification in 16 languages), and AfriQA (the first cross-lingual question answering dataset for African languages). Masakhane’s work functions as public infrastructure — freely accessible datasets and models that commercial players can build on, reducing the data cold-start problem for new entrants.
Lanfrica functions as the registry layer — a participatory documentation framework cataloguing African language research, datasets, and NLP projects across the continent’s 2,500-plus languages. For any team building in this space, Lanfrica is the starting point for understanding what resources exist for a given language before committing to a data collection programme.
Jacaranda Health (Kenya) has demonstrated a working vertical deployment with its open-source UlizaLlama, an LLM supporting five African languages for maternal health applications. It is a proof-of-concept that the stack — however incomplete — can already support production-grade specialised deployments in high-priority sectors.
The commercial pull
The infrastructure problem would be easier to solve if commercial demand were clearly defined. It is beginning to be. Three buyer categories are emerging.
Telcos are the most obvious. MTN’s 280 million subscribers span markets where English is a second or third language for most users. Safaricom’s M-PESA processes transactions for 35 million Kenyans, many of whom would be better served by Swahili-first AI interfaces than English-first ones. Airtel is deploying AI across 14 markets. All three need African-language AI for customer service, fraud detection, and value-added services — and none can build the underlying language stack themselves at the pace the market demands.
Fintechs face the same constraint. OPay, Moniepoint, and Wave are each building AI-assisted financial services for user bases that are majority non-English-speaking. The KYC and customer support interfaces that power these products at scale need to work in Hausa, Yoruba, and Igbo if they are to serve northern Nigeria at the depth that Lagos-market products already do.
Governments are the third buyer — and potentially the largest. NITDA’s digital literacy mandate, public service AI deployments in Kenya and Ghana, and the AU’s sovereign AI agenda all require language infrastructure that no Western AI provider is building as a priority.
The foundation model question
The most consequential debate in African language AI is not which company has the best model today. It is whether African-language AI can reach commercial viability through fine-tuning and adaptation of existing foundation models — or whether it requires purpose-built foundation models trained primarily on African language data.
The commercial argument for fine-tuning is speed and cost: building a foundation model from scratch is a multi-hundred-million-dollar undertaking. The technical argument for purpose-built models is quality: for languages where training data is genuinely scarce, a model pre-trained on predominantly English and European data may carry structural biases that fine-tuning cannot remove.
Lelapa AI has taken the resource-efficient adaptation path. NITDA’s GovNet compute play gestures toward something more ambitious. The answer will depend less on the technical debate than on whether African institutional and commercial buyers generate enough demand — and enough revenue — to justify the infrastructure investment that purpose-built African-language foundation models would require.
TechCabal Insights estimated in 2025 that AI could add $1 trillion to Africa’s GDP by 2035. Almost none of that potential is realised if the AI systems delivering it cannot speak to the majority of the continent’s users in their own languages.
BETAR.africa sought comment from Lelapa AI and NITDA on the commercial and infrastructure developments described in this article. Responses had not been received by publication time.